面上项目:大规模数据小标注样本量下的大间隔深度表示学习分类方法研究
近年来, 弱监督学习因其不需要大量细粒度的昂贵标注, 在计算机视觉领域受到了越来越多的关注. 其中, 弱监督目标检测(weakly supervised object detection)旨在只有图像整体类别标签的监督下完成对多类别多实例物体的定位, 与此相似, 弱监督目标定位(WSOL, weakly supervised object location)则旨在完成对单一类别物体的定位.
于中山大学智能视觉语言学习实验室实习的本科生麦金杰, 在杨猛导师的指导下, 针对WSOL问题, 提出了一种新型的网络对抗擦除学习方法 (Erasing Integrated Learing, 嵌入擦除). 目前, 此项工作已经被CVPR 2020接受, 并将在会议中oral展示.
Related work
Zhou et al. 在CVPR 2016上提出的CAM, class activation map是解决WSOL问题的经典方法. 该方法通过引入GAP, global average pooling以及阈值分割的方法, 可以在只对CNN分类网络稍加修改的基础上, 实现生成CAM图对感兴趣物体进行定位. 但该方法存在的缺陷即是分类网络CNN往往只会注意物体最显著的部分
此后, 涌现了许多基于对抗擦除的方法. 其基本的思路是在特征图擦除掉网络注意力最显著的部分, 它们可以大致归结为下列四类: a)Step-wise的擦除策略, 即先预训练一个分类CNN, 随后擦除掉显著性区域再训练一次达到学习物体全局的效果, 但存在效率较低的问题; b)Multi-branch的擦除策略, 在一个分支中进行擦除, 但需要对网络进行较大改动, 同时增加了额外的参数; c) 随机的擦除策略, 在网络训练的前向过程中随机擦除掉最显著的部分, 但存在损失部分信息, 导致精度无法进一步提高的问题.
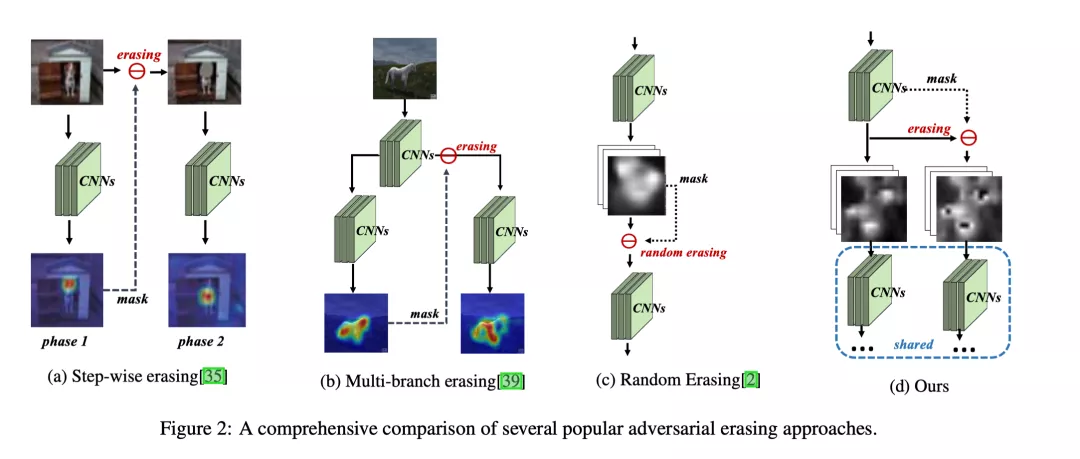
EIL
因此, 为了解决上述问题, 作者提出了一种新型的对抗擦除策略, (ErasingIntegrated Learing, 嵌入擦除). EIL通过将擦除步骤融合进CNN的单次前向过程中, 即选择在feature map层面, 将经过擦除后的feature map和未经擦除的feature map都输入到下一级网络中, 产生多个损失来引导网络注意物体的完整轮廓. 具体结构和算法步骤如下图所示.
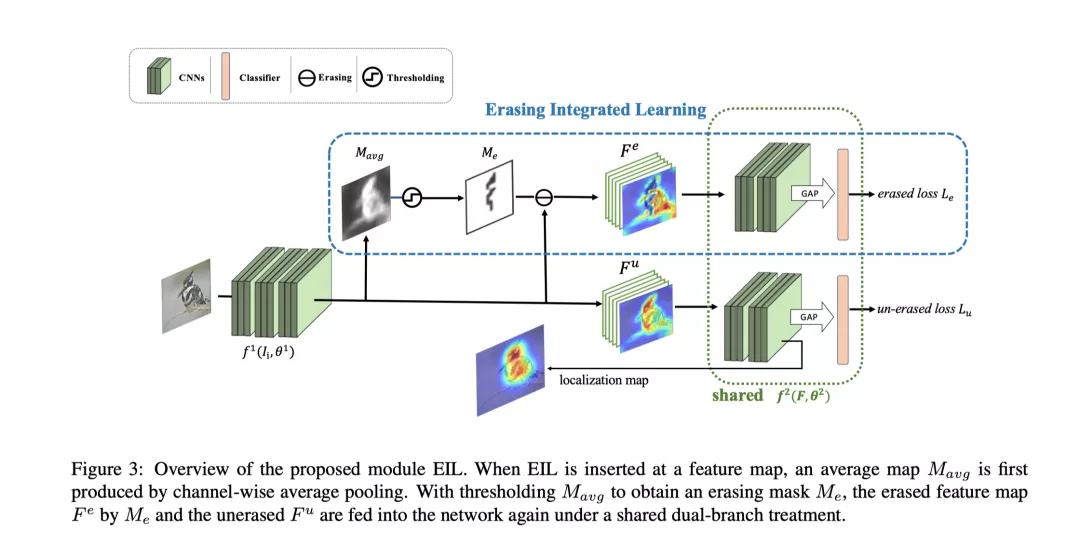
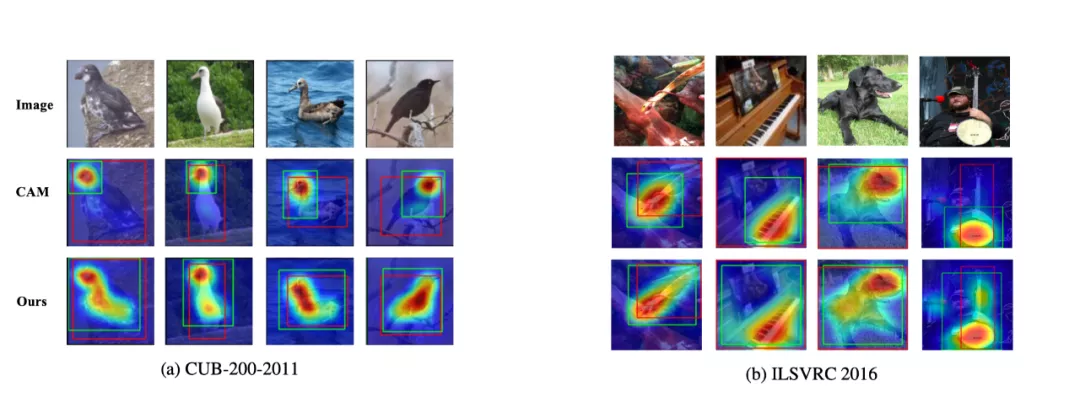
更进一步, 论文还提出了Multi-EIL的策略, 将多个EIL添加到网络中, 来指引网络学习多尺度多层级的物体特征, 从而使网络更好的定位识别到物体的完整轮廓. 实验结果表明,提出的EIL在VGG, GoogleNet等backbone和CUB, ILSVRC等数据集上均取得了当前最好表现.
IJCAI 2019 | 用于对象级情感分类的深度掩码记忆网络
对象级情感分类旨在识别句子中每个对象的情感。过往的深度记忆网络尽管取得了性能的提升,但是忽略了同一句子中各个对象之间的关系信息,并且其所利用的位置信息无法为分析对象的情感带来足够准确的信息。本论文提出了一个带有语义依赖和上下文矩的深层掩码记忆网络(DMMN-SDCM),它将依赖于当前分析对象的依存句法解析信息和对象间的关系信息集成到深层记忆网络中。实验结果体现了此模型达到了最先进的性能。
引言
对象级情感分类旨在识别句子中每个对象的情感极性(即积极,消极和中立)。相比文档级和句子级的情感分类,对象级情感分类可以提供更精细的情感分析结果。 例如,给定句子“价格便宜,但服务非常差”,对于对象“价格”,情感极性为积极,而对于对象“服务”,情感极性为消极。
当前,基于记忆网络的方法已经取得了不错的表现,然而这些方法简单地通过位置加权来生成依赖于对象的上下文记忆[1-2],且要么忽略了同一句子中对象的关系信息[1-2],要么只是简单地用隐式的方式指导对象关系学习[3-4],缺乏显性信息的指导。因此,本文针对这些问题,提出了一个带有语义依赖和上下文矩的深层掩码记忆网络(DMMN-SDCM)。本文具体的贡献如下:
用依存句法解析信息代替原有的位置信息集成到深度记忆网络中,以引导多跳注意力机制;
将依存句法解析信息集成到对象间建模中,以更好地利用附近对象提供的信息;
设计一个辅助任务来学习整个句子的情感分布,为当前分析对象的情感分析提供背景。
模型
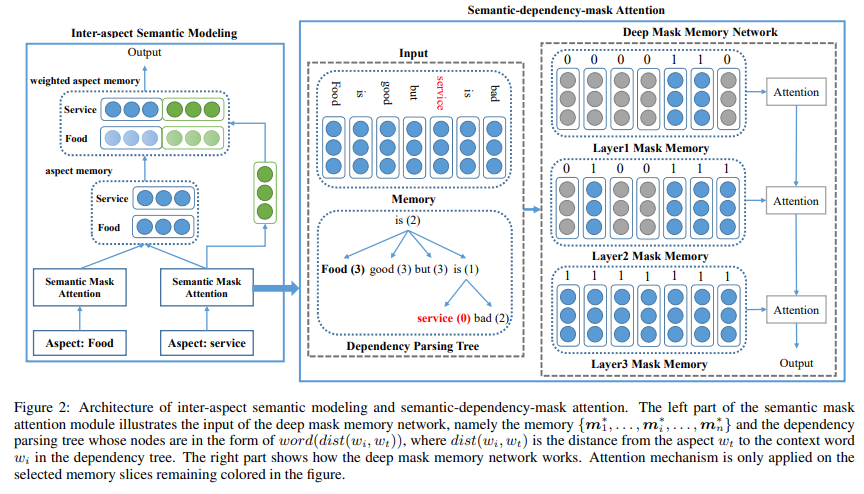
模型首先利用依存句法信息得到当前分析对象与上下文在依存句法树上的距离,然后根据依存句法距离动态生成记忆网络的初始上下文记忆,即底层选择依存句法距离较小的上下文,随着层数的增加,距离较大的上下文慢慢被考虑进来,最终,深层掩码记忆网络最后一层的输出即为依赖于当前分析对象的上下文特征。
另一方面,利用一个句子中的所有对象的上下文特征,模型通过简单的依存句法距离加权,得到依赖于当前对象的周围对象特征。
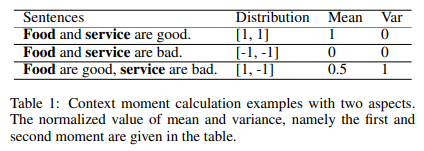
在一个句子中,周围对象可能与当前对象存在不同的关系,因此,本文设计了一个预测上下文矩的辅助任务。如下表所示,一阶矩(即均值)和二阶矩(即方差)在一定程度上分别刻画了句子中的总体情感信息和对象关系信息。因此,通过预测上下文矩的值,可以得到嵌入了句子情感信息和对象关系信息的特征,辅助当前对象的情感分类。
实验
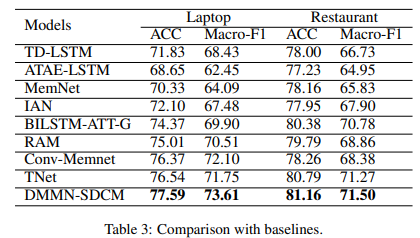
在SemEval 2014数据集上[5]的实验结果证明,DMMN-SDCM模型取得当前最优性能。
参考文献
[1] Duyu Tang, Bing Qin, and Ting Liu.Aspect level sentiment classification with deep memory network. arXiv preprintarXiv:1605.08900, 2016.
[2] Peng Chen, Zhongqian Sun, Lidong Bing,and Wei Yang. Recurrent attention network on memory for aspect sentimentanalysis. In EMNLP, pages 452–461, 2017.
[3] Devamanyu Hazarika, Soujanya Poria,Prateek Vij, Gangeshwar Krishnamurthy, Erik Cambria, and Roger Zimmermann.Modeling inter-aspect dependencies for aspect-based sentiment analysis. In NAACL,volume 2, pages 266–270, 2018.
[4] Navonil Majumder, Soujanya Poria, AlexanderGelbukh, Md Shad Akhtar, Erik Cambria, and
Asif Ekbal. Iarm: Inter-aspect relationmodeling with memory networks in aspect-based sentiment analysis. In EMNLP,pages 3402–3411, 2018.
[5] Maria Pontiki, Dimitris Galanis, John Pavlopoulos,Harris Papageorgiou, Ion Androutsopoulos,
and Suresh Manandhar. Semeval-2014 task 4:Aspect based sentiment analysis. SemEval, pages 27–35, 2014.
AAAI 2020 | 用于中文零代词消解的带有成对损失的分层注意力网络
近年来,用于中文零代词消解的神经网络方法并没有将零代词和候选先行词之间的双向注意力纳入考虑,且只是将该任务视为分类任务,而忽略了零代词的不同候选词之间的关系。 为了解决这些问题,本文提出了一种具有成对损失的分层注意力网络(HAN-PL),用于中文零代词解析。在提出的HAN-PL中,一个两层的注意力模型被设计来学习零代词和候选先行词更具区分性的特征表示。此外,模型通过引入正确先行词的相似性约束和成对的最大间隔损失,使特征更具区分性。在OntoNotes 5.0数据集上的实验证明了本文的模型在中文零代词消解任务中达到了最先进的性能。
引言
零代词指由于语言连贯性而被省略的成分,在中文文档中普遍存在。如果零代词与相关文本中的一个或多个词(通常由共指链表示)相关,则该零代词可被消解。在下图中,*pro*1是可消解的,“警察”为正确的消解结果,而*pro*2是不可消解的。这些用于消解零代词的词被称为先行词。如何正确消解零代词是语义理解中一个具有挑战性的课题,引起了广泛关注。

当前,解决零代词消解的方法要么没有考虑零代词和候选先行词之间的相互作用[1-2],要么只是针对零代词到候选先行词的方向应用了单向注意力机制[3-4],削弱了模型的特征表示能力。另外,这些方法仅将消解任务转换为分类任务(即候选词是否为零代词的先行词),而忽略了零代词的不同候选词之间的关系(即正确的候选词相似且其得分比错误的候选词高得多)[1-4]。因此,本文针对这些问题,提出了一种具有成对损失的分层注意力网络(HAN-PL)。本文具体的贡献如下:
提出了分层注意力机制,用交互的形式学习零代词和候选先行词的特征;
用成对的最大间隔损失指导模型的优化,比过往方法中使用的交叉熵损失更合理;
考虑到正确先行词的相似性约束,从而利用共指链提供的全局信息。
模型
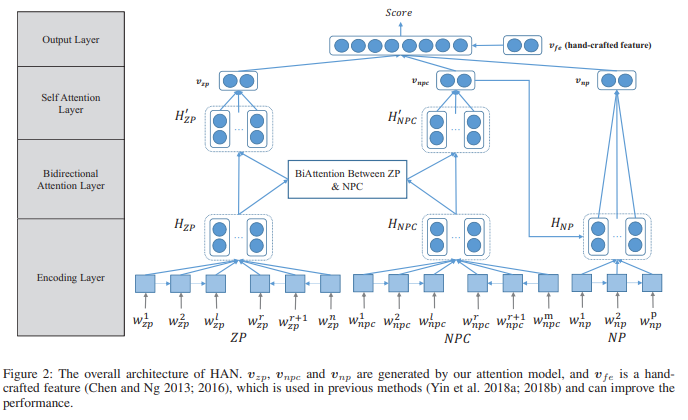
分层注意力机制的架构图如上所示,在第一层,双向注意力机制被应用来实现零代词和候选先行词之间的交互。在第二层,自注意力机制被应用来捕获零代词和候选先行词本身关键的部分,最终,零代词和候选先行词的特征表示被拼接在一起,用来计算消解分数。
受[5]启发,为了引导模型的训练,本文不同的情况(即正确候选先行词和错误候选词分别是否为空集),设计了不同的最大间隔损失函数。
为了引导模型的训练,本文不同的情况(即正确候选先行词和错误候选词分别是否为空集),设计了不同的最大间隔损失函数。
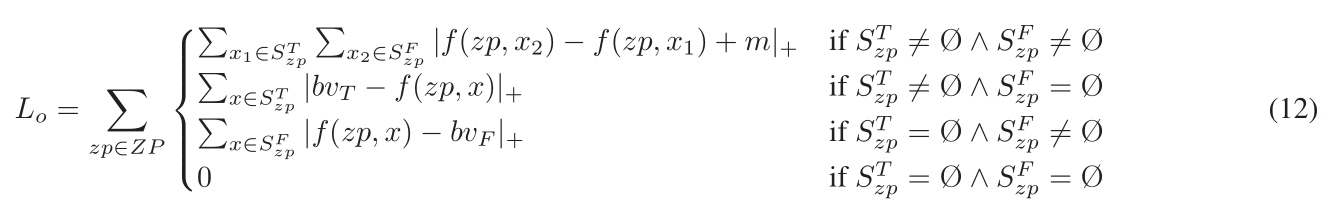
以上的最大间隔损失函数只考虑了正负候选词之间的关系,忽略了正样本之间的相似度,因此,本文针对此点,设计了如以下公式的正样本相似性约束。
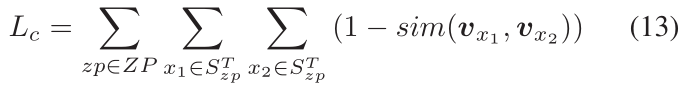
最终,最大间隔损失、正样本相似性约束以及二范数约束被加权求和来引导模型训练。
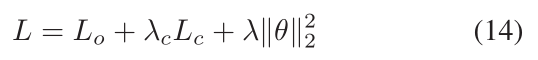
实验
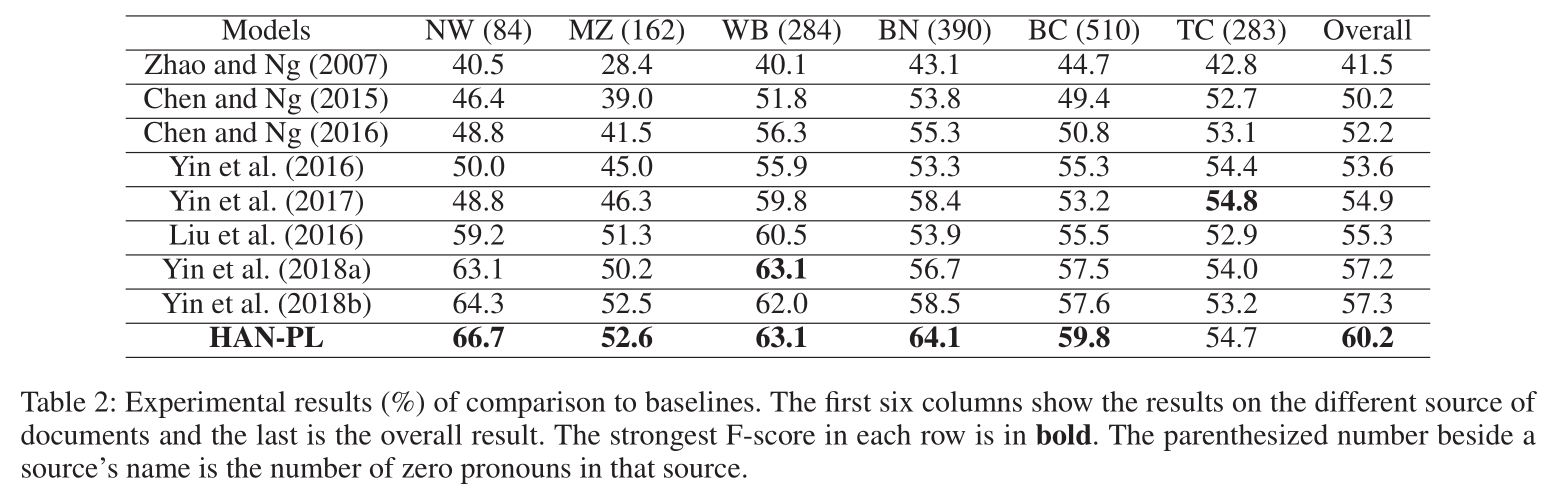
实验结果证明,HAN-PL模型取得当前最优性能。
参考文献
[1] Chen, C., and Ng, V. 2016. Chinese zeropronoun resolution with deep neural networks. In ACL, volume 1, 778–788.
[2] Yin, Q.; Zhang, Y.; Zhang, W.; Liu, T.;and Wang, W. Y. 2018a. Deep reinforcement learning for chinese zero pronounresolution. arXiv preprint arXiv:1806.03711.
[3] Liu, T.; Cui, Y.; Yin, Q.; Zhang, W.;Wang, S.; and Hu, G. 2016. Generating and exploiting large-scale pseudo trainingdata for zero pronoun resolution. arXiv preprint
arXiv:1606.01603.
[4] Yin, Q.; Zhang, Y.; Zhang, W.; Liu, T.;and Wang, W. Y. 2018b. Zero pronoun resolution with attention-based neural network.In Proceedings of the 27th International Conference on ComputationalLinguistics, 13–23.
[5] Clark, K., and Manning, C. D. 2016.Deep reinforcement learning for mention-ranking coreference models. arXiv preprintarXiv:1609.08667.
PR 2020 | 基于显著图谱和增量更新策略的弱监督分割
引言
仅利用图像层面的弱监督语义分割算法容易受到类别物体共同出现场景的影响,导致网络不能准确区分预期的物体类别。现有的其它弱监督方法(比如 WILDCAT)面临这样的问题。因而除了使用图像层面的类别标注信息外,需要引入一些额外的先验信息帮助弱监督方法解决此类问题。
出于拍照的聚焦偏向性,与类别无关的显着性图谱倾向于关注共现类别的前景对象上,因此提供了一种抑制同时出现背景区域的解决方案。图像的显着性图谱在已有的方法里没有被充分利用,而是简单地用以提取类激活图无法获得的背景线索。相反,课题组以不同的方式利用图像显着图,引入了一个前景特征聚合策略,有效结合已有的类别信息,比现有处理方法得到更加准确的分割结果。此外,为了应对分类网络固有的局部关注问题,即局限性地关注区分性较高的物体区域,课题组提出了一种增量式的掩码更新策略。
模型
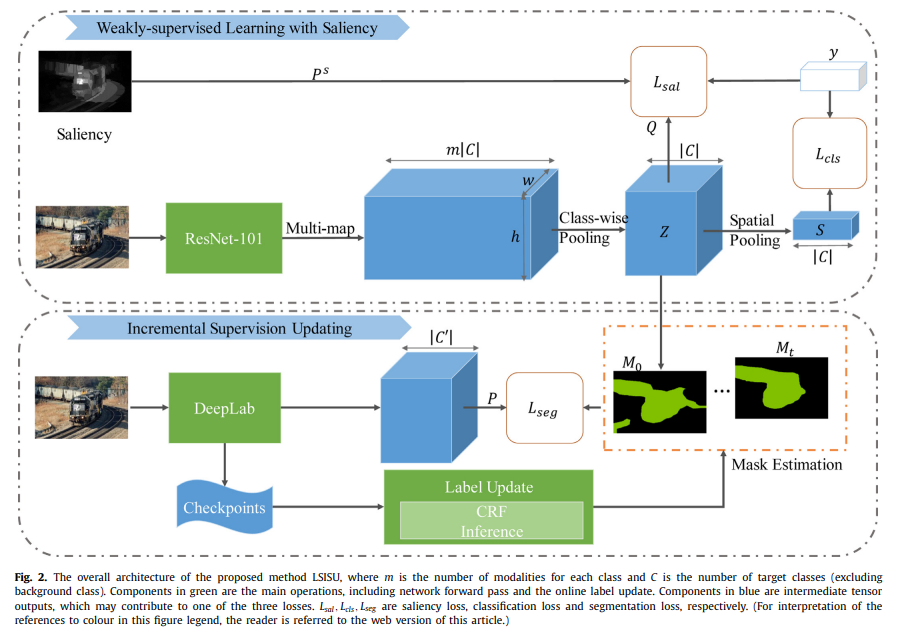
本课题组提出了一种基于显著图谱和增量更新策略的弱监督语义分割方法(LSISU),提出了一个基于图像显著性的优化目标,有效地帮助弱监督的深度网络解决物体同步出现的问题。同时,充分利用基于类别池化的策略来提供高质量的预估掩码。接着在分割网络的训练阶段,初始掩码会被逐步地增量式更新(ISU),逐渐扩充到物体的非显著性区域。总的流程图如下图所示:
实验
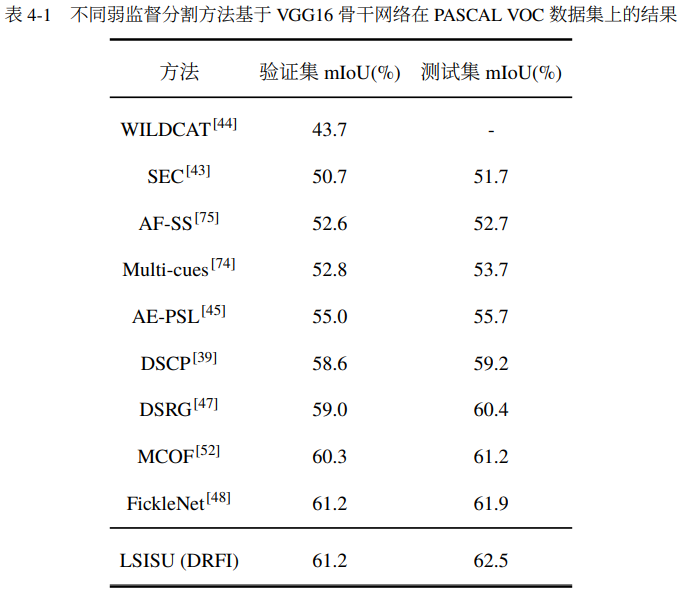
我们在PASCALVOC 2012和Microsoft COCO数据集上进行了实验。表1列出了在PASCAL VOC 验证集和测试集上由弱监督模型获得的最新结果。为了进行公平的比较,我们仅考虑基于 VGG16 构建并在具有类别标签的 10k 图像下训练的模型,且表1列出的几乎所有方法都采用了显著图。我们可以看到LSISU 优于现有的最新方法。